Importing Modules
In this section we are looking at importing modules from global repository using pip and locally made libraries.
Understanding Pip and Importing in Python
What is pip?
pip is the package installer for Python. It allows you to install and manage additional libraries and dependencies that are not included in the Python standard library. To use pip, you typically run commands in the terminal.
Installing Packages with pip
To install a Python package using pip, you can use the following command in your terminal or command prompt:
For example, to install the requests library, you would run:
To install a specific version of a package, use == followed by the version number, like so:
How Importing Works in Python
When you use import in Python, the interpreter searches for the module in the following order:
- Current Working Directory: It first checks if the module exists in the directory where the Python script is located.
- Standard Library: Next, it checks if the module is part of Python's built-in standard library.
- Installed Packages: Finally, it looks in the
site-packagesdirectory, where packages installed bypipare stored.
Types of Imports
-
Standard Imports: Import the entire module. For example:
-
Selective Imports: Import specific functions or classes from a module. For example:
-
Aliased Imports: Create a shorthand name for a module or function. For example:
Exercise 1: Built-in Modules
Instructions:
-
Open a new Python file and name it
exercise1.py. -
Import the
mathmodule. -
Use the
math.sqrt()function to find the square root of 16. -
Use
math.pito print the value of Pi. -
Save and run the script.
Exercise 2: Using Aliases with Modules
Instructions:
-
Open a new Python file named
exercise2.py. -
Import the
datetimemodule asdt. -
Use
dt.datetime.now()to print the current date and time. -
Save and run the script.
Exercise 3: Installing and Using External Modules
Instructions:
-
Open a new Python file and name it
exercise3.py. -
Use
pipto install therequestsmodule by running the following command in your terminal or command prompt: -
In
exercise3.py, import therequestsmodule and use it to get data from a URL (for example,https://api.github.com). Print the status code of the response. -
Save and run the script.
Exercise 4: Selective Imports and Installing Specific Versions
Instructions:
-
Install
pandasandmatplotliblibraries with specific versions.-
In your terminal, run the following commands to install specific versions:
Do you have an error?
-
You should always check if the package version exists... you will likely have an error.
-
Check https://pypi.org/
-
-
-
Open a new Python file named
exercise4.py. -
From
pandas, import onlyDataFrameandSeriesasdfandser. -
Print the installed versions of
pandasandmatplotlibto verify them. -
Save and run the script.
Exercise 5: Basic Data Analysis with Pandas
Instructions:
-
Create a new Python file and name it
exercise5.py. -
Import
pandasaspd. -
Create a small DataFrame using the following data:
-
Print the DataFrame and display summary statistics using
.describe(). -
Save and run the script.
Exercise 6: Data Visualization with Matplotlib
Instructions:
-
Create a new Python file named
exercise6.py. -
Import
matplotlib.pyplotasplt. -
Use the following data to create a bar chart showing the ages of individuals:
-
Label the axes as "Names" and "Ages" and add a title "Ages of Individuals".
-
Display the plot using
plt.show(). -
Save and run the script.
Using a requirements.txt File
A requirements.txt file lists all the packages your project depends on, along with their versions. This file is helpful for sharing your project and ensuring others install the exact package versions you used.
To create a requirements.txt file with the installed packages and their versions, run:
The command pip freeze > requirements.txt is used to generate a requirements.txt file listing all currently installed Python packages along with their versions. Here’s how it works:
-
pip freeze:-
This part of the command outputs a list of installed packages in your Python environment, with each package version pinned to the specific version currently installed.
-
For example, the output might look like this:
-
The
==notation ensures that the exact versions are captured, which is crucial for creating a reproducible environment.
-
-
>(Redirect Operator):- The
>symbol redirects the output ofpip freezeto a file instead of displaying it in the terminal. - Here, we use
>to create or overwrite a file calledrequirements.txtwith the output frompip freeze.
- The
-
Creating
requirements.txt:- The command
pip freeze > requirements.txtwill save all installed packages and their versions intorequirements.txt.
- The command
Why Use requirements.txt?
-
Reproducibility: Using a
requirements.txtfile allows others to install the same package versions, ensuring the code runs the same way. -
Easy Setup: To install all packages listed in a
requirements.txtfile, simply use: -
This will output a file listing all dependencies, which can then be installed with:
Exercise 7: Creating a requirements.txt File
Instructions:
-
Install the
requestsandpandaspackages if you haven't already, using: -
In your terminal, create a
requirements.txtfile with the following command: -
Open the
requirements.txtfile to verify thatrequestsandpandas==1.3.5are listed.
Exercise 8: Installing from a requirements.txt File
Instructions:
-
To simulate using the
requirements.txtfile in a new environment, you can uninstall an installed package, like so: -
Use the
requirements.txtfile to reinstall the necessary packages by running: -
Verify the installation by running a script that imports
requestsandpandas, ensuring they are correctly installed.
Exercise 9: Creating a Data Science Program Using a Provided Dataset with a Requirements File
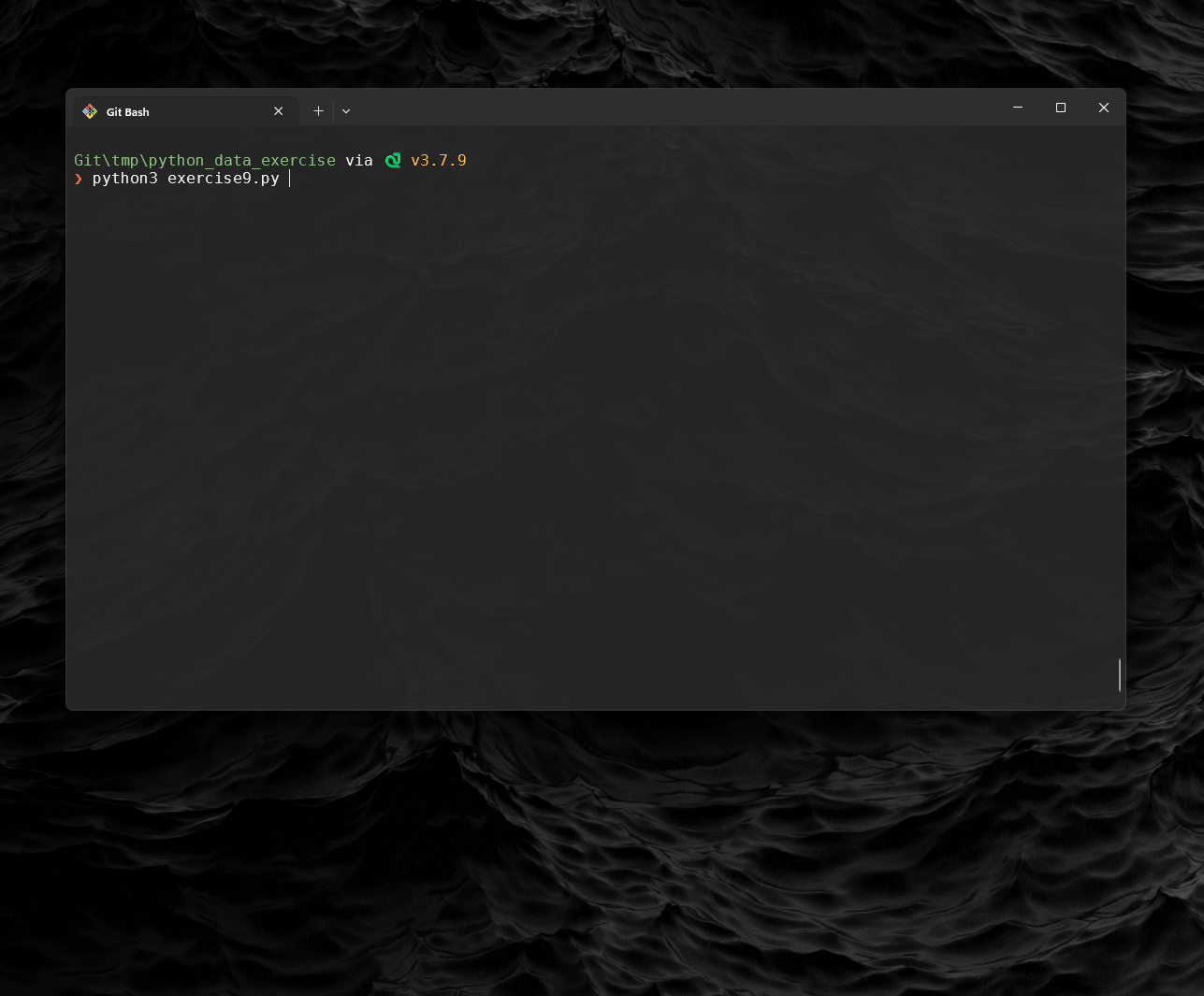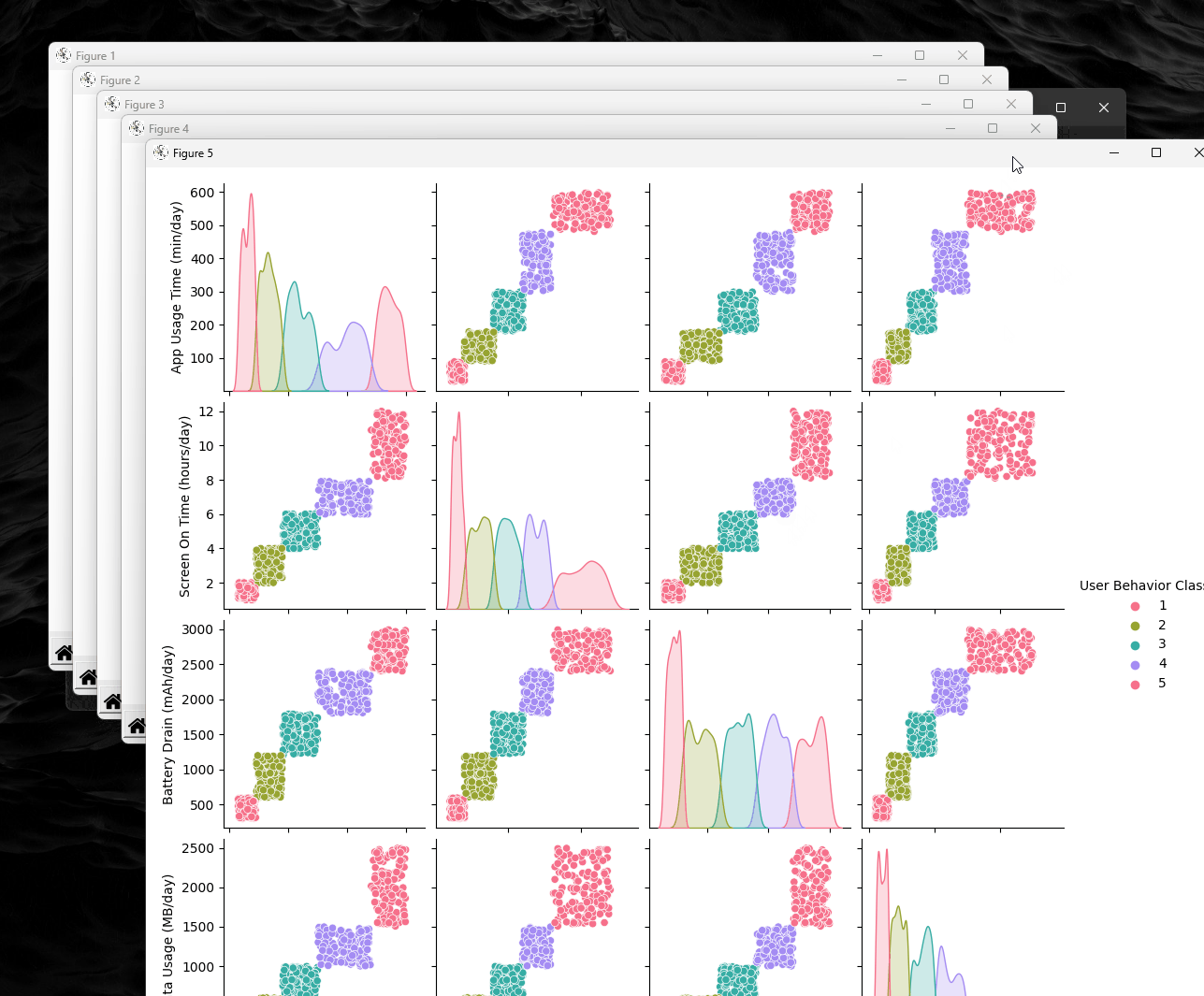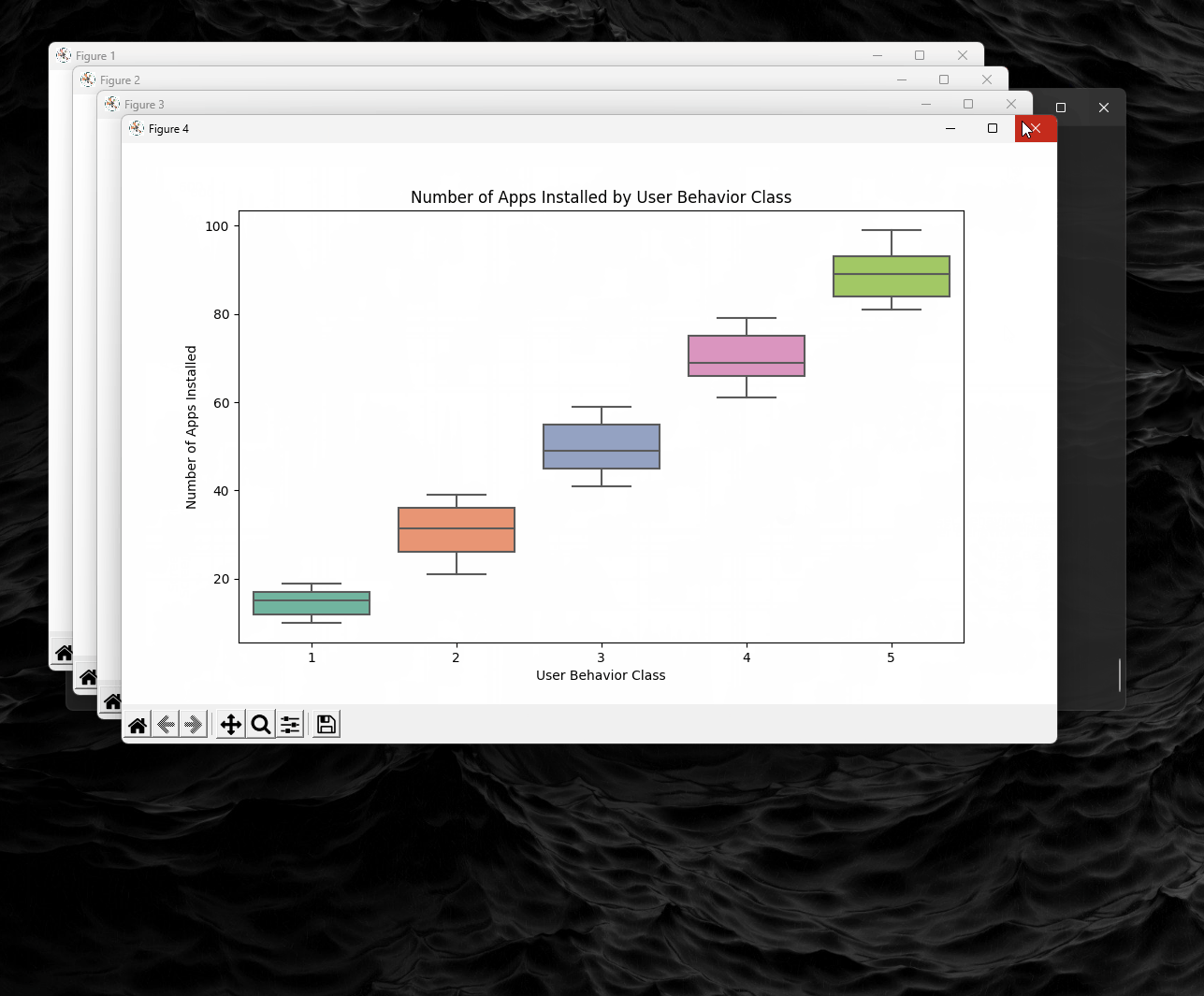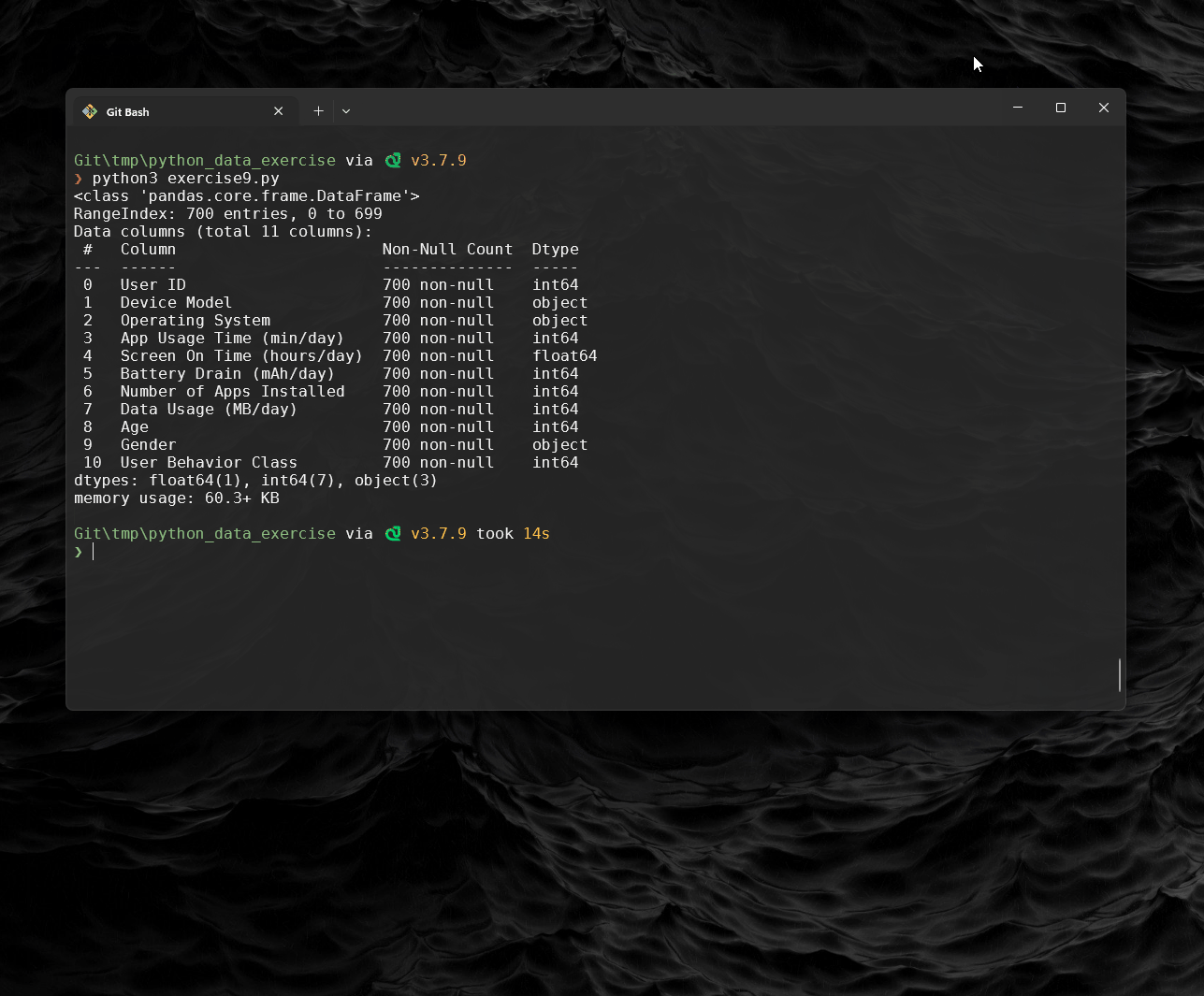
The following dataset includes 700 entries and 11 columns, covering various user behavior metrics such as "App Usage Time," "Screen On Time," "Battery Drain," "Data Usage," and demographic data ("Age" and "Gender").
- Download the dataset here:
- Documentation for each package used:
- pandas: https://pandas.pydata.org/docs/
- numpy: https://numpy.org/doc/
- matplotlib: https://matplotlib.org/stable/index.html
- seaborn: https://seaborn.pydata.org/
- We are going to load this dataset and analyze key metrics like "App Usage Time (min/day)" and "Screen On Time (hours/day)".
- Group the data by "Operating System" and "User Behavior Class" to perform a comparative analysis.
- Visualize the distribution of "App Usage Time" by Batter Drain or behavior class using histograms or box plots.
In this exercise, you’ll work with a provided dataset and specify dependencies using a requirements.txt file for easy environment setup.
Instructions:
-
Create a
requirements.txtfile: Open your terminal in the project directory and use the following command to specify versions and createrequirements.txt: -
Install from
requirements.txt: Once created, install dependencies directly fromrequirements.txtby running: -
Write the analysis program: In a Python file (
exercise9.py), write a program that:- Loads the dataset
user_behavior_dataset.csv. - Displays a summary of the dataset and calculates statistics on "App Usage Time (min/day)" and "Screen On Time (hours/day)".
- Compares "App Usage Time (min/day)" across "Gender" and visualizes the distribution using a box plot.
- Loads the dataset
-
Supressed code.. [58 lines]
# Import necessary libraries for data analysis and visualization import pandas as pd # For data manipulation import numpy as np # For numerical operations import matplotlib.pyplot as plt # For plotting import seaborn as sns # For enhanced data visualization from matplotlib.offsetbox import OffsetImage, AnnotationBbox # For annotations on plots (if needed) # Load the dataset data = pd.read_csv('./user_behavior_dataset.csv') # Display the first few rows of the dataset print(data.head()) # Display the shape of the dataset (rows, columns) print("Dataset shape:", data.shape) # Show information about the dataset, including column types and non-null values data.info() # Display descriptive statistics for numeric columns print(data.describe()) # Check for missing values in the dataset print("Missing values per column:\\n", data.isnull().sum()) # Plot 1: Distribution of App Usage Time plt.figure(figsize=(10, 6)) sns.histplot(data['App Usage Time (min/day)'], kde=True, color="blue") plt.title('Distribution of App Usage Time (min/day)') plt.xlabel('App Usage Time (min/day)') plt.ylabel('Frequency') # Plot 2: Battery Drain vs Data Usage by User Behavior Class plt.figure(figsize=(10, 6)) sns.scatterplot(x='Battery Drain (mAh/day)', y='Data Usage (MB/day)', hue='User Behavior Class', data=data, palette='plasma') plt.title('Battery Drain vs Data Usage by User Behavior Class') plt.xlabel('Battery Drain (mAh/day)') plt.ylabel('Data Usage (MB/day)') plt.legend(title='User Behavior Class') # Plot 3: Distribution of Battery Drain for Android vs iOS plt.figure(figsize=(10, 6)) sns.kdeplot(data=data, x='Battery Drain (mAh/day)', hue='Operating System', palette='coolwarm', fill=True) plt.title('Distribution of Battery Drain for Android vs iOS') plt.xlabel('Battery Drain (mAh/day)') plt.ylabel('Density') # Plot 4: Number of Apps Installed by User Behavior Class plt.figure(figsize=(10, 6)) sns.boxplot(x='User Behavior Class', y='Number of Apps Installed', data=data, palette='Set2') plt.title('Number of Apps Installed by User Behavior Class') plt.xlabel('User Behavior Class') plt.ylabel('Number of Apps Installed') # Plot 5: Pairplot of selected behavioral metrics sns.pairplot(data[['App Usage Time (min/day)', 'Screen On Time (hours/day)', 'Battery Drain (mAh/day)', 'Data Usage (MB/day)', 'User Behavior Class']], hue='User Behavior Class', palette='husl') # Display all plots plt.show()